I want to start with an announcement for Canvas users: at InstructureCon, there will be an AMA-style panel with engineering leadership from Instructure, and you can submit questions in advance here. I submitted a question about data-mining, and also one about search (yep, they mine our data but we cannot search our own course content; details). So, chime in at the Canvas Community in advance and, if you'll be at InstCon, the panel itself is Thursday, Jul 11 at 4:20-5:00 PM.

And now, this week in datamongering:
An important new blog post from Ben Williamson on TurnItIn: Automating mistrust. I see TurnItIn as being the ominous harbinger of an approach we now see spreading throughout the related world of the LMS, so this is an important read for all educators, not just those of us who teach writing. quote "Turnitin is also reshaping relationships between universities and students. Students are treated by default as potential essay cheats by its plagiarism detection algorithm. [...] Turnitin’s continued profitability depends on manufacturing and maintaining mistrust between students and academic staff, while also foregrounding its automated algorithm over teachers’ professional expertise." Ben's post contains lots of links in turn to pieces by Jesse Stommel, John Warner, Lucas Introna, and others and he also discusses an aspect of TurnItIn operations that I find especially troubling: the WriteCheck service which allows students to TurnItIn-proof their work before they submit it, for a steep fee of course. The student who first alerted me to the existence of WriteCheck dubbed it "Write-Me-A-Check" ($8 per paper, discounts for repeat users).
Plus more about TurnItIn in the news this week at CampusTechnology: Turnitin Partnership Adds Plagiarism Checking to College Admissions. In response to that, an excellent comment from Susan Blum:

Susan would know; she is the author of My Word!: Plagiarism and College Culture (the Kindle is just $7.99, people!). Table of contents: 1 A Question of Judgment / 2 Intertextuality, Authorship, and Plagiarism / 3 Observing the Performance Self / 4 Growing Up in the College Bubble / 5 No Magic Bullet.
Meanwhile, this piece from Anya Kamenetz at NPR has a theme that is really relevant to the question of (mis)trust: instead of monitoring, we need to be mentoring! At Your Wits' End With A Screen-Obsessed Kid? Read This. quote "Heitner advises that families like this one need to switch from monitoring to mentoring. Policing their kids' device use isn't working. They need to understand why their kids are using devices and what their kids get out of those devices so they can help the kids shift their habits." (Devorah Heitner is the author of Screenwise: Helping Kids Thrive (and Survive) in Their Digital World.) This same advice applies IMO to teachers: if students are not writing well, policing with TurnItIn is not going to give us the information we need to do better. Instead, we need to understand why students write well, or not, and what we can do to create more meaningful writing/learning experiences.
And now, moving on from TurnItIn this week to... Amazon. There is a great piece by Will Oremus at OneZero: Amazon Is Watching. quote "Imagine Ring surveillance cameras on cars and delivery drones, Ring baby monitors in nurseries, and Amazon Echo devices everywhere from schools to hotels to hospitals. Now imagine that all these Alexa-powered speakers and displays can recognize your voice and analyze your speech patterns to tell when you’re angry, sick, or considering a purchase. A 2015 patent filing reported last week by the Telegraph described a system that Amazon called “surveillance as a service,” which seems like an apt term for many of the products it’s already selling."

Amazon has yet to make its big play for education; will it be Alexa in schools everywhere...? More on EchoDot for kids, plus a lawsuit on Amazon child surveillance). And don't forget the drones: With Amazon’s New Drone Patent, The Company’s Relationship With Surveillance Is About To Get Even More Complicated.
And on Amazon Rekognition, see this important piece: Amazon's Facial Analysis Program Is Building A Dystopic Future For Trans And Nonbinary People by Anna Merlan and Dhruv Mehrotra at Jezebel. This is a long and detailed article, with both big-picture information and also results of a specific Rekognition experiment. quote "Rekognition misgendered 100% of explicitly nonbinary individuals in the Broadly dataset. This isn’t because of bad training data or a technical oversight, but a failure in engineering vocabulary to address the population. That their software isn’t built with the capacity or vocabulary to treat gender as anything but binary suggests that Amazon’s engineers, for whatever reason, failed to see an entire population of humans as worthy of recognition."
And to complete the trifecta this week, here's more on Bill Gates's ambitions for higher ed via John Warner at IHE: Bill Gates, Please Stay Away from Higher Education. quote "These large, seemingly philanthropic efforts undertaken by billionaires like Gates are rooted in a desire to preserve the status quo where they sit atop the social order. Rather than putting his money into the hands of education experts or directly funding schools or students, he engineers programs, which replicate his values."
And for a related fail in education this week: AltSchool’s out: Zuckerberg-backed startup that tried to rethink education calls it quits. quote "AltSchool wooed parents and tech investors with a vision of bringing the classroom into the digital age. Engineers and designers on staff developed software for assisting teachers, and put it to work at a group of small schools in the Bay Area and New York run by the startup. At those outposts, kids weren’t just students; they served as software testers, helping AltSchool refine its technology for sale to other schools." Specifically on the subject of students as software testers, see these concerns expressed much earlier about exploiting students as data sources from Connie Loizos at TechCrunch: AltSchool wants to change how kids learn, but fears have surfaced that it’s failing students. quote "Compounding their anger these days is AltSchool’s more recent revelation that its existing network of schools, which had grown to seven locations, is now being pared back to just four — two in California and two in New York. The move has left parents to wonder: did AltSchool entice families into its program merely to extract data from their children, then toss them aside?"
And yes, there are more items that I bookmarked... but surely that's enough for this week. Eeek.
On an up side, thanks to Tom Woodward I learned about this data-mongering resistance tool: it opens a 100 tabs in your browser designed to distort your profile. I'm not sure I want non-stop streetwear ads... but it would definitely skew my profile which currently delivers an endless stream of ads for books (no surprise) and for, yep, CanvasLMS, ha ha, as if I am in the market for an LMS. More at TrackThis.link.


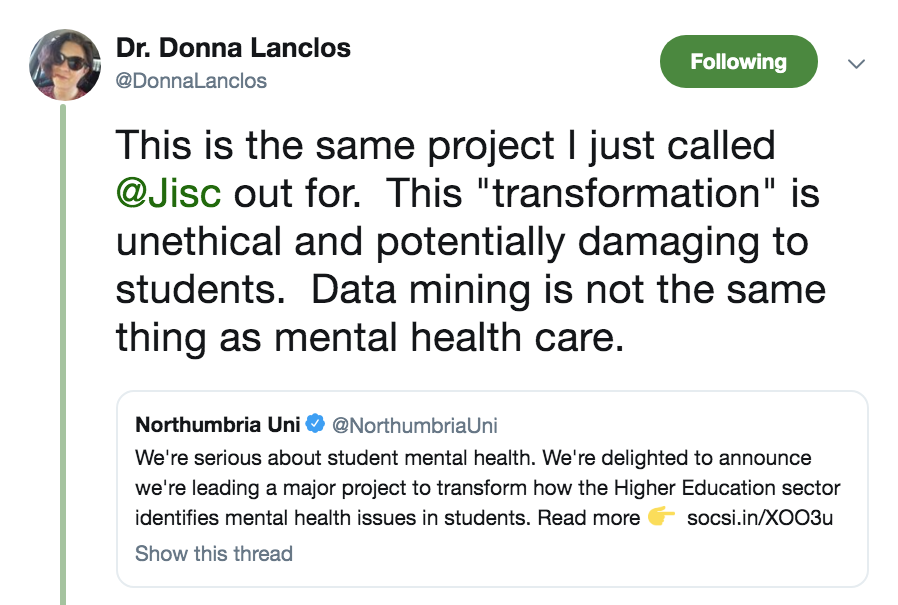
And the graphic this week also comes from Tom at Twitter:

Plus XKCD on predictive modeling........

No docks at midnight... but I'll see you here again next week. And if you have #datamongering items to share at Twitter, use the hashtag and we can connect.






























{kind=link}