So, in this blog post, I want to say something about both of those topics: first, I will explain why I have zero expectation that Instructure will be able to build useful algorithms; then, I will share an article I read this week about student data-gathering in China that shows what could happen if teachers and students do not speak out now to protest these moves by Instructure and other ed-tech harvesters of student data.
Canvas and the Assumption of Sameness
Anyone who's used Canvas knows that it is committed to an assumption of sameness. You cannot even modify your course menus without installing an external tool that then "redirects" menu items, even when the "redirect" is going to a page in your own course. Moreover, you have to install a new instance of the redirect tool app from the app store for every change you make.

I have seven separate instances of the redirect tool installed in my Canvas courses (you can see here: Myth.MythFolklore.net), and no matter how much I want to rename the "Grades" menu item there is nothing I can do in order to change its name. When we used D2L I was able to change the name to "Declarations" (which suits my class better), but Canvas adamantly refuses to let me change the menu labels.
Why must everything be the same, named the same, look the same, etc.? Apparently students will be "confused" if things are not exactly the same, or so I've been told again and again by Canvas enthusiasts. That paternalistic, condescending assumption is something that has always bothered me about Canvas; I think it should be up to students and teachers to make choices about what works and what doesn't. Based on my 20 years of teaching experience, I don't think students are so easily confused as Canvas assumes that they are. Learning how to navigate difference is something students need to do in school, and minimizing difference is not necessarily doing anybody a favor. In any case, both students and teachers need freedom to customize their own learning spaces in the ways they think are best.
But Canvas is all about minimizing difference. Sure, you can use the redirect tool if you want, and you can use other plug-ins and tools to bring external content into Canvas (that is the method I rely on most), but there is an abiding assumption of sameness in Canvas, and there always has been. It's not a bug; it's a feature.
Now, of course, as Instructure launches its data mining and machine learning efforts, it is going to be all the more important to keep things the same. Not so that the students will not be confused, but so that the computer will not be confused. Because if you are going to try to bring together all the data, across schools and across curriculums as Dan Goldsmith claims, then you really need to make sure things are the same across those schools and curriculums. That's what will allow Instructure to combine the data to create "the most comprehensive database on the educational experience in the globe" (again quoting Goldsmith).
But here's the thing: not all courses have the same design. Not all teachers have the same approach. Not all students learn the same way; they are not white lab rats genetically engineered to respond in the exact same way to the exact same stimuli in the exact same conditions, as a computer does. Nothing in human learning is ever exactly the same.
Canvas, however, wants to make everything the same. Sometimes the results of that sameness are just annoying, like having to add the redirect tool app again and again to a course. At other times, though, the results are dangerous, like when Canvas decided to start labeling my students' work, incorrectly, with big red labels in the Gradebook. LATE said Canvas, and MISSING said Canvas, even though my students' assignments are not late and not missing. Here's a real screenshot from a real student's Gradebook display... and none, not one, of these labels is appropriate:
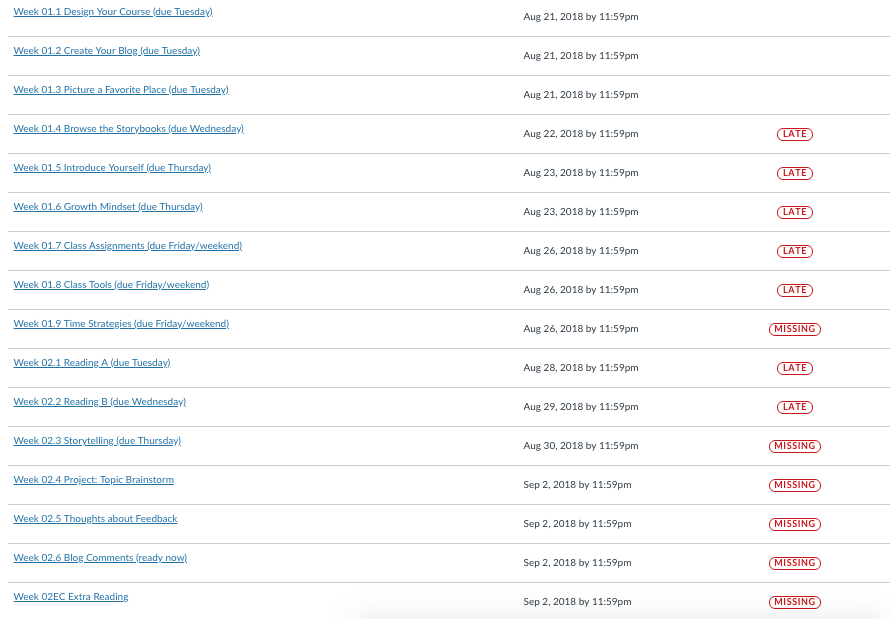
Canvas started adding these labels as part of the new Gradebook. I documented the problem extensively at the Canvas Community back in Fall 2017, at which point they rolled the feature back, but then, like a good zombie, it returned from the dead again this semester when my school made everyone switch to the new Gradebook. Nightmare. I'm not going to repeat all the details here, but you can see my posts with the #red ink tag documenting the story at the Canvas Community (that last post about the future of Canvas is the one that prompted the Community Managers to prohibit my future blogging at the Community).
Suffice to say, Canvas has no idea how my courses are designed, and they have no right to be labeling my students' work that way in the Gradebook. There is no place for punitive, deficit-driven grading in my classes (more about that here), and that means there is no place for Canvas's red labels. Those labels are just wrong, completely and absolutely wrong. And my students were, understandably, upset when the red ink missing and late labels showed up out of nowhere. I don't mind apologizing to students for mistakes that I make, but I sure don't like apologizing to students for mistakes that the computer software is making. Especially when it's computer software that I am required to use by my school for grading purposes because of FERPA.
This is just one example from one teacher, but I know that we could document thousands upon thousands of examples of ways in which individual teachers and students are doing work that Instructure's "machine" simply cannot understand. And because the machine cannot grasp all the different ways we do things, that means it cannot actually learn from what we are doing. Even worse, it will learn wrongly and do the wrong things, like putting all the wrong labels on my students.
In short, it seems to me that anyone who believes in Goldsmith's claims about "the most comprehensive database on the educational experience in the globe" does not really understand what educational experiences (PLURAL) are all about.
In short, it seems to me that anyone who believes in Goldsmith's claims about "the most comprehensive database on the educational experience in the globe" does not really understand what educational experiences (PLURAL) are all about.
From Bad to Worse: Really Big Data in China

Power of hashtags: I love the way the investigation begins with a hashtag: #ThankGodIGraduatedAlready. A hashtag, and also a government plan:
In July 2017, China’s highest governmental body, the State Council, released an ambitious policy initiative called the Next Generation Artificial Intelligence Development Plan (NGAIDP). The 20,000-word blueprint outlines China’s strategy to become the leading AI power in both research and deployment by 2030 by building a domestic AI industry worth nearly $150 billion. It advocates incorporating AI in virtually all aspects of life, including medicine, law, transportation, environmental protection, and what it calls “intelligent education.”
So, in the great data-arms race to have "the most comprehensive database on the educational experience in the globe," Instructure is really going to have to up their game. Just clicks and eyeballs are not going to be enough. Now they are going to need our faces too.
Much like the MOOC-boosters of yesteryear, this data collection is presented as something that is really for the students, for their benefit, for their own good:
“Do you know the two types of students teachers pay the most attention to?” Zhang asks. “The smartest and the naughtiest.” Hanwang’s CCS technology was born from the desire to care for every kid in the classroom, even the “often-ignored, average students,” he adds.
The desire to care. Uh-huh. "Class Care" is the name of the system, CCS. But is this how students want to be cared for? As the article documents, the students are not happy about this surveillance:
Privacy? The Chinese ed-tech vendor Hanwang is using the same excuse that no doubt Instructure will use: privacy is being respected because data is only being used "in-house" and not shared with a third party:
Back in the classroom, my questions about the cameras evoke curiosity among the boys. Jason tells them everything he knows. There is a gasp, followed by silence. “I want to smash it,” one boy says. “Shhh!” Another boy shakes a warning glance at Hanwang’s camera behind us. “What if the camera just captured everything?”Some students are indeed disabling the cameras in their classrooms, despite their justified fears. Brave students: bravo!
Privacy? The Chinese ed-tech vendor Hanwang is using the same excuse that no doubt Instructure will use: privacy is being respected because data is only being used "in-house" and not shared with a third party:
CCS doesn’t violate the students’ privacy. We don’t share the reports with third parties, and you see that on the in-class pictures we send to the parents, all the faces other than their child’s are blurred out.
It begins innocently enough, as you can see in this exchange with a principal at a school that has installed the system:
Niulanshan’s principal, Wang Peidong, who has over 40 years of teaching experience, is also dismissive of CCS. “It’s not very useful,” he says. “You think a teacher standing on a podium needs AI to tell her if a student is sleeping in class?”Don't think it can happen here? Think again: check out this eerily similar graphic for a rah-rah-data article in the Chronicle of Higher Education:
“Then why is it still used in your classrooms?” I ask.
“Zhang Haopeng is an alumnus of our school. He wants to do experiments here, so we let him. We don’t need to pay for it anyway,” he says, already walking away to get to his next meeting.

Labels in the Gradebook. Labels in the classroom.
Wrong labels. Punitive labels.
My sense of despair here is enormous, and I am glad that I will be retired from teaching before we have handed everything of importance over to our new data-driven robo-overlords.
Don't get me wrong. I believe in using data: small data, data that fits the educational experience: The Value of SMALL Data and Microassignments. We need to let the educational experience drive the data first. Otherwise, it's just wrong data. And big wrong data is dangerous data. You cannot let that data drive our education.
For more, read Audrey Watters. And Cathy O'Neil's Weapons of Math Destruction: How big data increases inequality and threatens democracy.
And speak out. Money talks, and money is ultimately what is driving all of these conversations. So, we cannot just talk: we have to shout! I'm going to keep on shouting. I admire the students in China who are disconnecting the surveillance cameras in their classrooms in protest, and I am going to keep on protesting the overreach of AI in Canvas and their (mis)use of my students' data (even if that conversation cannot happen in the Canvas Community itself).
More to come.













